I’ve been thinking a lot lately about how to bring more interactivity and immediacy into legal research instruction—especially for those topics that never quite “click” the first time. One idea that’s stuck with me is vibe-coding (see Sam Harden’s recent piece on vibecoding for access to justice). The concept, loosely put, is about using code to quickly build lightweight tools that deliver a very specific, helpful experience—often more intuitive than polished, and always focused on solving a narrow, real-world problem.
That framing resonated with me as both an educator and a librarian. In particular, it got me thinking about Boolean searching—an area where students routinely struggle. Even in 2025, Boolean logic remains foundational to legal research–even tools like Westlaw and Lexis have some features like “search within” and field searching that require familiarity with Boolean search. But despite its importance, it can feel abstract and mechanical when taught through static examples or lectures.
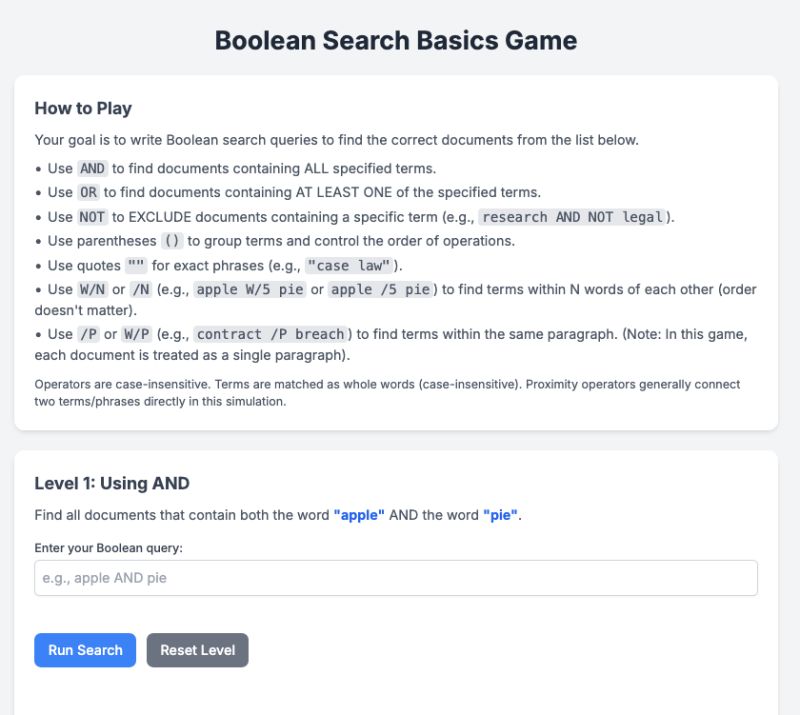
So I tried a bit of vibe-coding myself. I built a small, interactive Boolean search game using the Canvas feature in Google Gemini 2.5—it’s a simple web-based activity that gives users a chance to experiment with constructing Boolean expressions and get real-time feedback. It only took about 30 minutes to get a solid version running, and even in that rough form, it worked. The immediate engagement helps clarify the logic in a way that static examples rarely do. You can check it out and play here: https://gemini.google.com/share/436f0db98cef
I’ll be teaching Advanced Legal Research in the fall for the first time in a few years, and I’m planning to lean more into this kind of lightweight, interactive content. These micro-tools don’t have to be elaborate to be effective, and they can go a long way toward reinforcing concepts that students often struggle with in more traditional formats.
Have an idea for a micro-tool to use in teaching? They’re easy, fun, and a little addicting to make. You’ll just need access to the paid version of ChatGPT, Claude, or Gemini. (You can also experiment with AI coding assistants like Replit or Bolt.New. Both have limited free versions.) Provide your idea, perhaps some additional context in the form of a file or webpage, and you’re off to the races. My prompt that resulted in a working version of this Boolean game was literally just “Make an interactive game that will help researchers understand the basics of Boolean Search,” and I attached some slides I’ve previously used to teach the topic.
If you build something or you have an idea I’d love to hear about it!
This is a post from multiple authors: Rebecca Fordon (The Ohio State University), Deborah Ginsberg (Harvard Law Library), Sean Harrington (University of Oklahoma), and Christine Park (Harvard Law Library)
In late 2023, several legal research databases and start-up competitors announced their versions of ChatGPT-like products, each professing that theirs would be the latest and greatest. Since then, law librarians have evaluated and tested these products ad hoc, offering meaningful anecdotal evidence of their experience, much of which can be found on this blog and others. However, one-time evaluations can be time-consuming and inconsistent across the board. Certain tools might work better for particular tasks or subject matters than others, and coming up with different test questions and tasks takes time that many librarians might not have in their daily schedules.
It is difficult to test Large-Language Models (LLMs) without back-end access to run evaluations. So to test the abilities of these products, librarians can use prompt engineering to figure out how to get desired results (controlling statutes, key cases, drafts of a memo, etc.). Some models are more successful than others at achieving specific results. However, as these models update and change, evaluations of their efficacy can change as well. Therefore, we plan to propose a typology of legal research tasks based on existing computer and information science scholarship and draft corresponding questions using the typology, with rubrics others can use to score the tools they use.
Although we ultimately plan to develop this project into an academic paper, we share here to solicit thoughts about our approach and connect with librarians who may have research problem samples to share.
Difficulty of Evaluating LLMs
Let’s break down some of the tough challenges with evaluating LLMs, particularly when it comes to their use in the legal field. First off, there’s this overarching issue of transparency—or rather, the lack thereof. We often hear about the “black box” nature of these models: you toss in your data, and a result pops out, but what happens in between remains a mystery. Open-source models allow us to leverage tools to quantify things like retrieval accuracy, text generation precision, and semantic similarity. We are unlikely to get the back-end access we need to perform these evaluations. Even if we did, the layers of advanced prompting and the combination of tools employed by vendors behind the scenes could render these evaluations essentially useless.
Even considering only the underlying models (e.g., GPT4 vs Claude), there is no standardized method to evaluate the performance of LLMs across different platforms, leading to inconsistencies.Many different leaderboards evaluate the performance of LLMs in various ways (frequently based on specific subtasks). This is kind of like trying to grade essays from unrelated classes without a rubric—what’s top-notch in one context might not cut it in another. As these technologies evolve, keeping our benchmarks up-to-date and relevant is becoming an ongoing challenge, and without uniform standards, comparing one LLM’s performance to another can feel like comparing apples to oranges.
Then there’s the psychological angle—our human biases. Paul Callister’s work sheds light on this by discussing how cognitive biases can lead us to over-rely on AI, sometimes without questioning its efficacy for our specific needs. Combine this with the output-based evaluation approach, and we’re setting ourselves up for potentially frustrating misunderstandings and errors. The bottom line is that we need some sort of framework for the average user to assess the output.
One note on methods of evaluation: just before publishing this blog post, we learned of a new study from a group of researchers at Stanford, testing the claims of legal research vendors that their retrieval-augmented generation (RAG) products are “hallucination-free.” The group created a benchmarking dataset of 202 queries, many of which were chosen for their likelihood of producing hallucinations. (For example, jurisdiction/time-specific and treatment questions were vulnerable to RAG-induced hallucinations, whereas false premise and factual recall questions were known to induce hallucinations in LLMs without RAG.) The researchers also proposed a unique way of scoring responses to measure hallucinations, as well as a typology of hallucinations. While this is an important advance in the field and provides a way to continue to test for hallucinations in legal research products, we believe hallucinations are not the only weakness in such tools. Our work aims to focus on the concrete applications of these LLMs and probe into the unique weaknesses and strengths of these tools.
The Current State of Prompt Engineering
Since the major AI products were released without a manual, we’ve all had to figure out how to use these tools from scratch. The best tool we have so far is prompt engineering. Over time, users have refined various templates to better organize questions and leverage some of the more surprising ways that AI works.
As it turns out, many of the prompt templates, tips, and tricks we use with the general commercial LLMs don’t carry over well into the legal AI sphere, at least with the commercial databases we have access to. For example, because the legal AIs we’ve tested so far won’t ask you questions, researchers may not be able to have extensive conversations with the AI (or any conversation for some of them). So that means we must devise new types of prompts that will work in the legal AI sphere, and possibly work only in the AI sphere.
We should be able to easily design effective prompts because the data set the AIs use is limited. But it’s not always clear exactly what sources the AI is using. Some databases may list how many cases they have for a certain court by year; others may say “selected cases before 1980” without explaining how they were selected. And even when the databases provide coverage, it may not be clear exactly which of those materials the AI can access.
We still need to determine what prompt templates will be most effective across legal databases. More testing is needed. However, we are limited to the specific databases we can access. While most (all?) academic law librarians have access to Lexis+ AI, Westlaw has yet to release its research product to academics.
Developing a Task Typology
Many of us may have the intuition that there are some legal research tasks for which generative AI tools are more helpful than others. For example, we may find that generative AI is great for getting a working sense of a topic, but not as great for synthesizing a rule from multiple sources. But if we wanted to test that intuition and measure how well AI performed on different tasks, we would need to first define those tasks. This is similar, by the way, to how the LegalBench project approached benchmarking legal analysis—they atomized the IRAC process for legal analysis down to component tasks that they could then measure.
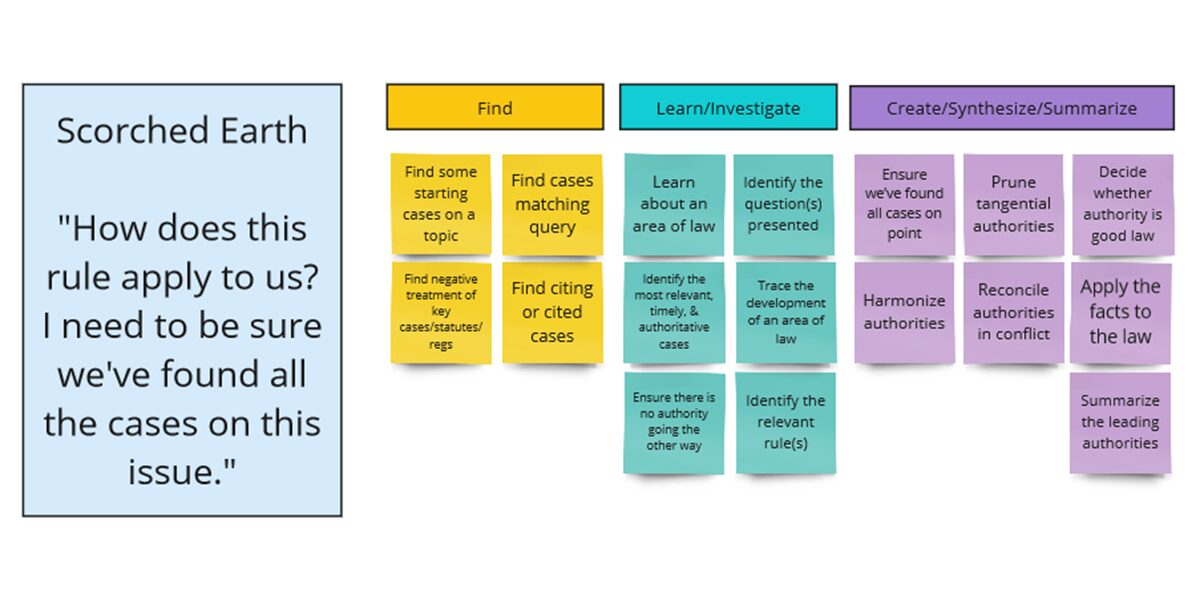
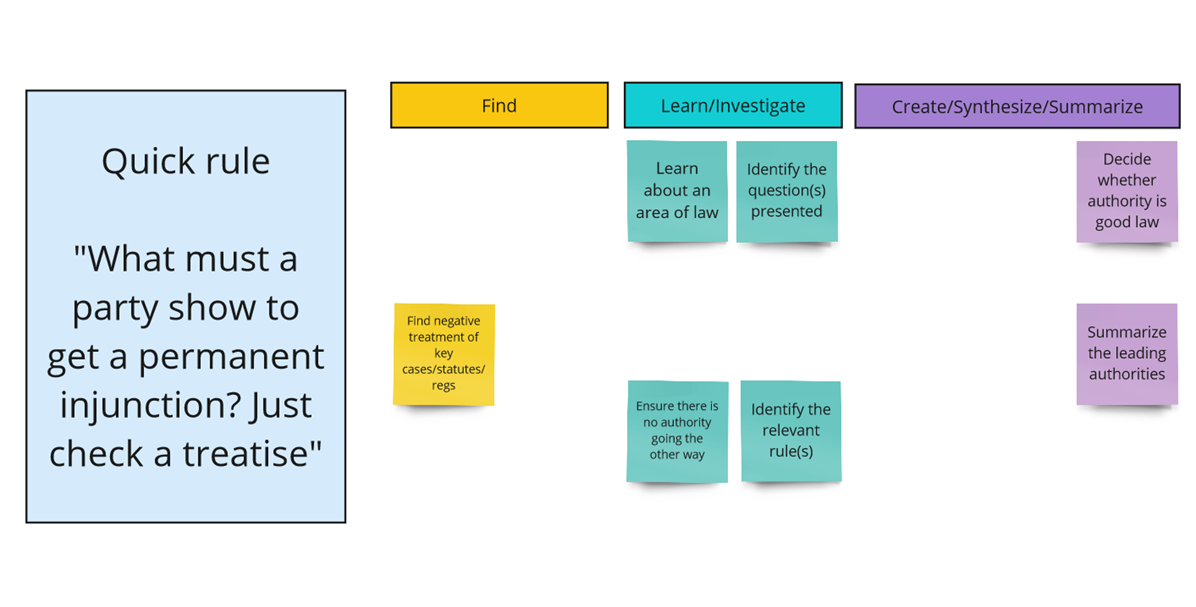
After looking at the legal research literature (in particular Paul Callister’s “problem typing” schemata and AALL’s Principles and Standards for Legal Research Competency), we are beginning to assemble a list of tasks for which legal researchers might use generative AI. We will then group these tasks according to where they fall in an information retrieval schemata for search, following Marchionini (2006) & White (2024), into Find tasks (which require a simple lookup), Learn & Investigate tasks (which require sifting through results, determining relevance, and following threads), and Create, Synthesize, and Summarize tasks (a new type of task for which generative AI is well-suited).
Notably, a single legal research project may contain multiple tasks. Here are a few sample projects applying a preliminary typology:
Again, we may have an initial intuition that generative AI legal research platforms, as they exist today, are not particularly helpful for some of these subtasks. For example, Lexis+AI currently cannot retrieve (let alone analyze) all citing references to a particular case. Nor could we necessarily be certain from, say, CoCounsel’s output, that it contained all cases on point. Part of the problem is that we cannot tell which tasks the platforms are performing, or the data that they have included or excluded in generating their responses. By breaking down problems into their component tasks, and assessing competency on both the whole problem and the tasks, we hope to test our intuitions.
Future Research
We plan on continually testing these LLMs using the framework we develop to identify which tasks are suitable for AIs and which are not. Additionally, we will draft questions and provide rubrics for others to use, so that they can grade AI tools. We believe that other legal AI users will find value in this framework and rubric.
I’ve been incredibly excited about the premium version of Claude 3 since its release on March 4, 2024, and for good reason. Now that my previous favorite chatty chatbot, ChatGPT-4, has gone off the rails, I was missing a competent chatbot… I signed up the second I heard on March 4th, and it has been a pleasure to use Claude 3 ever since. It actually understands my prompts and usually provides me with impressive answers. Anthropic, maker of the Claude chatty chatbot family, has been touting Claude’s accomplishments of supposedly beating its competitors on common chatbot benchmarks, and commentators on the Internet have been singing its praises. Just last week, I was so impressed by its ability to analyze information in news stories in uploaded files that I wrote a LinkedIn post also singing its praises!
Hesitation After Previous Struggles
Despite my high hopes for its legal research abilities after experimenting with it last week, I was hesitant to test Claude 3. I have a rule about intentionally irritating myself—if I’m not already irritated, I don’t go looking for irritation… Over the past several weeks, I’ve wasted countless hours trying to improve the legal research capabilities of ChatGPT-3.5, ChatGPT-4, Microsoft Copilot, and my legal research/memo writing GPTs through the magic of (IMHO) clever prompting and repetition. Sadly, I failed miserably and concluded that either ChatGPT-4 was suffering from some form of robotic dementia, or I am. The process was a frustrating waste, and I knew that Claude 3 doing a bad job of legal research too could send me over the edge….
Claude 3’s Wrote a Pretty Good Legal Memorandum!
Luckily for me, when I finally got up the nerve to test out the abilities of Claude 3, I found that the internet hype was not overstated. Somehow, Claude 3 has suddenly leapfrogged over its competitors in legal research/legal analysis/legal memo writing ability – it instantly did what would have taken a skilled researcher over an hour and produced a better legal memorandum which is probably better than that produced by many law students and even some lawyers. Check it out for yourself! Unless this link actually works for any Claude 3 subscribers out there, there doesn’t seem to be a way to actually link to a Claude 3 chat at this time. However, click here for the whole chat I cut and pasted into a Google Drive document, here for a very long screenshot image of the chat, or here for the final 1,446-word version of the memo as a Word document.
Comparing Claude 3 with Other Systems
Back to my story… The students’ research assignment for the last class was to think of some prompts and compare the results of ChatGPT-3.5, Lexis+ AI, Microsoft Copilot, and a system of their choice. Claude 3 did not exist at the time, but I told them not to try the free Claude product because I had canceled my $20.00 subscription to the Claude 2 product in January 2024 due to its inability to provide useful answers – all it would say was that it was unethical to answer every question and tell me to do it myself. When creating an answer sheet before class tomorrow which compares the same set of prompts on different systems, I decided to omit Lexis+ AI (because I find it useless) and to include my new fav Claude 3 in my comparison spreadsheet. Check it out to compare for yourself!
For the research part of the assignment, all systems were given a fact pattern and asked to “Please analyze this issue and then list and summarize the relevant Texas statutes and cases on the issue.” While the other systems either made up cases or produced just two or three actual real and correctly cited cases on the research topic, Claude 3 stood out by generating 7 real, relevant cases with correct citations in response to the legal research question. (And, it cited to 12 cases in the final version of its memo.)
It did a really good job of analysis too!
Generating a Legal Memorandum
Writing a memo was not part of the class assignment because the ChatGPT family was refusing the last few weeks,* and Bing Copilot had to be tricked into writing one as part of a short story, but after seeing Claude 3’s research/analysis results, I decided to just see what happened. I have many elaborate prompts for ChatGPT-4 and my legal memorandum GPTs, but I recalled reading that Claude 3 worked well with zero-shot prompting and didn’t require much explanation to produce good results. So, I decided to keep my prompt simple – “Please generate a draft of a 1500 word memorandum of law about whether Snurpa is likely to prevail in a suit for false imprisonment against Mallatexaspurses. Please put your citations in Bluebook citation format.”
From my experience last week with Claude 3 (and prior experience with Claude 2 which would actually answer questions), I knew the system wouldn’t give me as long an answer as requested. The first attempt yielded a pretty high-quality 735-word draft memo that cited all real cases with the correct citations*** and applied the law to the facts in a well-organized Discussion section. I asked it to expand the memo two more times, and it finally produced a 1,446-word document. Here is part of the Discussion section…
Implications for My Teaching
I’m thrilled about this great leap forward in legal research and writing, and I’m excited to share this information with my legal research students tomorrow in our last meeting of the semester. This is particularly important because I did such a poor job illustrating how these systems could be helpful for legal research when all the compared systems were producing inadequate results.
However, with my administrative law legal research class starting tomorrow, I’m not sure how this will affect my teaching going forward. I had my video presentation ready for tomorrow, but now I have to change it! Moreover, if Claude 3 can suddenly do such a good job analyzing a fact pattern, performing legal research, and applying the law to the facts, how does this affect what I am going to teach them this semester?
*Weirdly, the ChatGPT family, perhaps spurred on by competition from Claude 3, agreed to attempt to generate memos today, which it hasn’t done in weeks…
Note: Claude 2 could at one time produce an okay draft of a legal memo if you uploaded the cases for it, that was months ago (Claude 2 link if it works for premium subscribers and Google Drive link of cut and pasted chat). Requests in January resulted in lectures about ethics which resulted in the above-mentioned cancellation.
Recently, I’ve noticed a surge of new and innovative legal research tools. I wondered what could be fueling this increase, and set off to find out more.
The Moat
An image generated by DALL-E, depicting a castle made of case law reporters, with sad business children trying to construct their own versions out of pieces of paper. They just look like sand castles.
Historically, acquiring case law data has been a significant challenge, acting as a barrier to newcomers in the legal research market. Established players are often protective of their data. For instance, in an antitrust counterclaim, ROSS Intelligence accused Thomson Reuters of withholding their public law collection, claiming they had to instead resort to purchasing cases piecemeal from sources like Casemaker and Fastcase. Other companies have taken more extreme measures. For example, Ravel Law partnered with the Harvard Law Library to scan every single opinion in their print reporter collections.There’s also speculation that major vendors might even license some of their materials directly to platforms like Google Scholar, albeit with stringent conditions.
The New Entrants
Despite the historic challenges, several new products have recently emerged offering advanced legal research capabilities:
Descrybe.ai(founded 2023) – This platform leverages generative AI to read and summarize judicial opinions, streamlining the search process. Currently hosting around 1.6 million summarized opinions, it’s available for free.
Midpage (2022) – Emphasizing the integration of legal research into the writing process, users can employ generative AI to draft documents from selected source (see Nicola Shaver’s short writeup on Midpage here). Midpage is currently free at app.midpage.ai.
CoPilot (by LawDroid, founded 2016) – Initially known for creating chatbots, LawDroid introduced CoPilot, a GPT-powered AI legal assistant, in 2023. It offers various tasks, including research, translating, and summarizing. CoPilot is available in beta as a web app and a Chrome extension, and is free for faculty and students.
Paxton.ai(2023) – Another generative AI legal assistant, Paxton.ai allows users to conduct legal research, draft documents, and more. Limited free access is available without signup at app.paxton.ai, although case law research will require you to sign up for a free account.
With the Caselaw Access Project, launched in 2015, Ravel Law and Harvard Law Library changed the game. Through their scanning project, Harvard received rights to the case law data, and Ravel gained an exclusive commercial license for 8 years. (When Lexis acquired Ravel a few years later, they committed to completing the project.) Although the official launch date of free access is February 2024, we are already seeing a free API at Ravel Law (as reported by Sarah Glassmeyer).
Caselaw Access Project data is only current through 2020 (scanning was completed in 2018, and has been supplemented by Fastcase donations through 2020) and does not include digital-first opinions. However, this gap is mostly filled through CourtListener, which contains a quite complete set of state and federal appellate opinions for recent years, painstakingly built through their network of web scrapers and direct publishing agreements. CourtListener offers an API (along with other options for bulk data use).
And indeed, Caselaw Access Project and Free Law Project just recently announced a dataset called Collaborative Open Legal Data (COLD) – Cases. COLD Cases is a dataset of 8.3 million United States legal decisions with text and metadata, suitable for use in machine learning and natural language processing projects.
Most of the legal research products I mentioned above do not disclose their precise source of their case law data. However, both Descrybe.ai and Midpage point to CourtListener as a partner. My theory/opinion is that many of the others may be using this data as well, and that these new, more reliable and more complete sources of data are responsible for fueling some amazing innovation in the legal research sphere.
What Holes Remain?
Reviewing the coverage of CourtListener and Caselaw Access Project it appears to me that they have, when combined:
100% of all published U.S. case law from 2018 and earlier (state and federal)
100% of all U.S. Supreme Court, U.S. Circuit Court of Appeals, and state appellate court cases
There are, nevertheless, still a few holes that remain in the coverage:
Newer Reporter Citations. Newer appellate court decisions may not have reporter citations within CourtListener. These may be supplemented as Fastcase donates cases to Caselaw Access Project.
Newer Federal District Court Opinions. Although CourtListener collects federal decisions marked as “opinions” within PACER, these decisions are not yet available in their opinion search. Therefore, very few federal district court cases are available for the past 3-4 years. This functionality will likely be added, but even when it is, district courts are inconsistent about marking decisions as “opinions” and so not all federal district court opinions will make their way to CourtListener’s opinions database. To me, this brings into sharp relief the failure of federal courts to comply with the 2002 E-Government Act, which requires federal courts to provide online access to all written opinions.
State Trial Court Decisions. Some other legal research providers include state court trial-level decisions. These are generally not published on freely available websites (so CourtListener cannot scrape them) and are also typically not published in print reporters (so Caselaw Access Project could not scan them).
Tribal Law. Even the major vendors have patchy access to tribal law, and CourtListener has holes here as well.
The Elephant in the Room
Of course, another major factor in the increase in legal research tools may be simple economics. In August, Thomson Reuters acquired the legal research provider Casetext for the eye-watering sum of $650 million. And Casetext itself is a newer legal research provider, founded only in 2013. In interviews, Thomson Reuters cited Casetext’s access to domain-specific legal authority, as well as its early access to GPT-4, as key to its success.
What’s Next?
Both Courtlistener and Caselaw Acess Project have big plans for continuing to increase access to case law. CAP will launch free API access in February 2024, coordinating with LexisNexis, Fastcase, and the Free Law Project on the launch. CourtListener is planning a scanning project to fix remaining gaps in their coverage (CourtListener’s Mike Lissner tells me they are interested in speaking to law librarians about this – please reach out). And I’m sure we can expect to see additional legal research tools, and potentially entire LLMs (hopefully open source!), trained on this legal data.
Know of anything else I didn’t discuss? Let me know in the comments, or find me on social media or email.
LLMs have come a long way even in the time since I wrote my article in June. Three months of development time with this technology feels like three years – or maybe that’s just me catching up. Despite that, there are still a couple of nagging issues that I would like to see implemented to improve their usage to legal researchers. I’m hoping to raise awareness about this so that we can collectively ask vendors to add quality-of-life features to these tools for the benefit of our community.
Audit Trails
Right now the tools do not have a way for us to easily check their work. Law librarians have made a version of my argument for over a decade now. The legendary Susan Nevelow Mart famously questioned the opacity of search algorithms in legal research and evaluated their impact on legal research. More recently, I was in the audience at AALL2023 when the tenacious and brilliant Debbie Ginsburg from Harvard asked Fastcase, BLaw, Lexis, and Westlaw how we (law librarians) could evaluate the inclusivity of the dataset of cases that the new AI algorithms are searching. How do we know if they’ve missed something if we don’t know what they’re searching and how complete it is?
As it stands, the legal research AI that I’ve demoed do not give you a summary of where they have gone and what they have done. An “audit trail” (as I’m using this expression) is a record of which processes were used to achieve a specific task, the totality of the dataset, and why they chose the results to present to the user. This way if something goes wrong, you can go back and look at what steps were taken to get the results. This would provide an extra layer of security and confidence in the process.
Why Do We Need This?
These tools have introduced an additional layer of abstraction that separates legal researchers from the primary documents they are studying, altering how legal research is conducted. While the new AI algorithms can be seen as a step forward, they can undermine the precision that boolean expressions once offered, which allowed researchers to predict the type of results they would encounter with more certainty. Coverage maps are still available to identify gaps in the data for some of these platforms but, there is a noticeable shift towards less control over the search process, calling for a thoughtful reassessment of the evolving dynamics in legal research techniques.
More importantly, we (law librarians) are deep enough into these processes and technology to be highly skeptical and evaluate the output with a critical eye. Many students and new attorneys may not. I have told this story at some of my presentations but a recent graduate called me with a Pacific Reporter citation for a case that they could not find on Westlaw. This person was absolutely convinced that they were doing something wrong and had spent around an hour searching for this case because “this was THE PERFECT case” for their situation. It ended up being a fabrication from ChatGPT but the alumni had to call me to discover that. This is obviously a somewhat outdated worry, since Rebecca Fordon has gamed all of us up on the steps being taken to reduce hallucinations (and OpenAI got a huge amount of negative publicity from the, now infamous, ChatGPT Lawyer).
My point is less about the technology and more about the incentives set in place – if there is a fast, easy way to do this research then there will inevitably be people who are going to uncritically accept those results. “That’s their fault and they should get in trouble,” you say? Probably, but I plan to write about the duty of technological competency and these tools in a future post, so we’ll have to hash that out together later. Also, what if there was a fast, easy way to evaluate the results of these tools…
What Could Be Done
Summarizing the steps involved in research seems like it would be a feasible task for Westlaw, Lexis, Blaw, et al. to implement. They already have to use prompting to tell the LLM where to go and how to search; we’re just asking for a summary of those steps to be replicated somewhere so that we can double-check it. Could they take that same prompting and place a prompt around that says something to the effect of, “Summarize the steps taken in bullet points” and then place that into a drop-down arrow so that we could check it? Could they include hyperlinks to coverage maps in instances where it would be useful to the researcher to know how inclusive the search is? In instances where they’re using RAG, could they include a prompt that says something to the effect of, “Summarize how you used those underlying documents to generate this text?”
As someone who has tinkered with technology, all of these seem like reasonable requests that are well within the ability of these tools. I’m interested to hear if there are reasons why we couldn’t have these features or if people have other features they would like. Please feel free to post your ideas in the comments or email me.
Hallucinations in generative AI are not a new topic. If you watch the news at all (or read the front page of the New York Times), you’ve heard of the two New York attorneys who used ChatGPT to create fake cases entire cases and then submitted them to the court.
After that case, which resulted in a media frenzy and (somewhat mild) court sanctions, many attorneys are wary of using generative AI for legal research. But vendors are working to limit hallucinations and increase trust. And some legal tasks are less affected by hallucinations. Understanding how and why hallucinations occur can help us evaluate new products and identify lower-risk uses.
* A brief aside on the term “hallucinations”. Some commentators have cautioned against this term, arguing that it lets corporations shift the blame to the AI for the choices they’ve made about their models. They argue that AI isn’t hallucinating, it’s making things up, or producing errors or mistakes, or even just bullshitting. I’ll use the word hallucinations here, as the term is common in computer science, but I recognize it does minimize the issue.
With that all in mind, let’s dive in.
What are hallucinations and why do they happen?
Hallucinations are outputs from LLMs and generative AI that look coherent but are wrong or absurd. They may come from errors or gaps in the training data (that “garbage in, garbage out” saw). For example, a model may be trained on internet sources like Quora posts or Reddit, which may have inaccuracies. (Check out this Washington Post article to see how both of those sources were used to develop Google’s C4, which was used to train many models including GPT-3.5).
But just as importantly, hallucinations may arise from the nature of the task we are giving to the model. The objective during text generation is to produce human-like, coherent and contextually relevant responses, but the model does not check responses for truth. And simply asking the model if its responses are accurate is not sufficient.
In the legal research context, we see a few different types of hallucinations:
Citation hallucinations. Generative AI citations to authority typically look extremely convincing, following the citation conventions fairly well, and sometimes even including papers from known authors. This presents a challenge for legal readers, as they might evaluate the usefulness of a citation based on its appearance—assuming that a correctly formatted citation from a journal or court they recognize is likely to be valid.
Hallucinations about the facts of cases. Even when a citation is correct, the model might not correctly describe the facts of the case or its legal principles. Sometimes, it may present a plausible but incorrect summary or mix up details from different cases. This type of hallucination poses a risk to legal professionals who rely on accurate case summaries for their research and arguments.
Hallucinations about legal doctrine. In some instances, the model may generate inaccurate or outdated legal doctrines or principles, which can mislead users who rely on the AI-generated content for legal research.
In my own experience, I’ve found that hallucinations are most likely to occur when the model does not have much in its training data that is useful to answer the question. Rather than telling me the training data cannot help answer the question (similar to a “0 results” message in Westlaw or Lexis), the generative AI chatbots seem to just do their best to produce a plausible-looking answer.
This does seem to be what happened to the attorneys in Mata v. Avianca. They did not ask the model to answer a legal question, but instead asked it to craft an argument for their side of the issue. Rather than saying that argument would be unsupported, the model dutifully crafted an argument, and used fictional law since no real law existed.
How are vendors and law firms addressing hallucinations?
Although vendors and firms are often close-lipped about how they have built their products, we can observe a few techniques that they are likely using to limit hallucinations and increase accuracy.
First, most vendors and firms appear to be using some form of retrieval-augmented generation (RAG). RAG combines two processes: information retrieval and text generation. The model takes the user’s question and passes it (perhaps with some modification) to a database. The database results are fed to the model, and the model identifies relevant passages or snippets from the results, and again sends them back into the model as “context” along with the user’s question.
This reduces hallucinations, because the model receives instructions to limit its responses to the source documents it has received from the database. Several vendors and firms have said they are using retrieval-augmented generation to ground their models in real legal sources, including Gunderson, Westlaw, and Casetext.
To enhance the precision of the retrieved documents, some products may also use vector embedding. Vector embedding is a way of representing words, phrases, or even entire documents as numerical vectors. The beauty of this method lies in its ability to identify semantic similarities. So, a query about “contract termination due to breach” might yield results related to “agreement dissolution because of violations”, thanks to the semantic nuances captured in the embeddings. Using vector embedding along with RAG can provide relevant results, while reducing hallucinations.
Another approach vendors can take is to develop specialized models trained on narrower, domain-specific datasets. This can help improve the accuracy and relevance of the AI-generated content, as the models would be better equipped to handle specific legal queries and issues. Focusing on narrower domains can also enable models to develop a deeper understanding of the relevant legal concepts and terminology. This does not appear to be what law firms or vendors are doing at this point, based on the way they are talking about their products, but there are law-specific data pools becoming available so we may see this soon.
Finally, vendors may fine-tune their models by providing human feedback on responses, either in-house or through user feedback. By providing users with the ability to flag and report hallucinations, vendors can collect valuable information to refine and retrain their models. This constant feedback mechanism can help the AI learn from its mistakes and improve over time, ultimately reducing the occurrence of hallucinations.
So, hallucinations are fixed?
Even though vendors and firms are addressing hallucinations with technical solutions, it does not necessarily mean that the problem is solved. Rather, it may be that our our quality control methods will shift.
For example, instead of wasting time checking each citation to see if it exists, we can be fairly sure that the cases produced by legal research generative AI tools do exist, since they are found in the vendor’s existing database of case law. We can also be fairly sure that the language they quote from the case is accurate. What may be less certain is whether the quoted portions are the best portions of the case and whether the summary reflects all relevant information from the case. This will require some assessment of the various vendor tools.
We will also need to pay close attention to the databases results that are fed into retrieval augmented generation. If those results don’t reflect the full universe of relevant cases, or contain material that is not authoritative, then the answer generated from those results will be incomplete. Think of running an initial Westlaw search, getting 20 pretty good results, and then basing your answer only on those 20 results. For some questions (and searches), that would be sufficient, but for more complicated issues, you may need to run multiple searches, with different strategies, to get what you want.
To be fair, the products do appear to be running multiple searches. When I attended the rash of AI presentations at AALL over the summer, I asked Jeff Pfeiffer of Lexis how he could be sure that the model had all relevant results, and he mentioned that the model sends many, many searches to the database not just one. Which does give some comfort, but leads me to the next point of quality control.
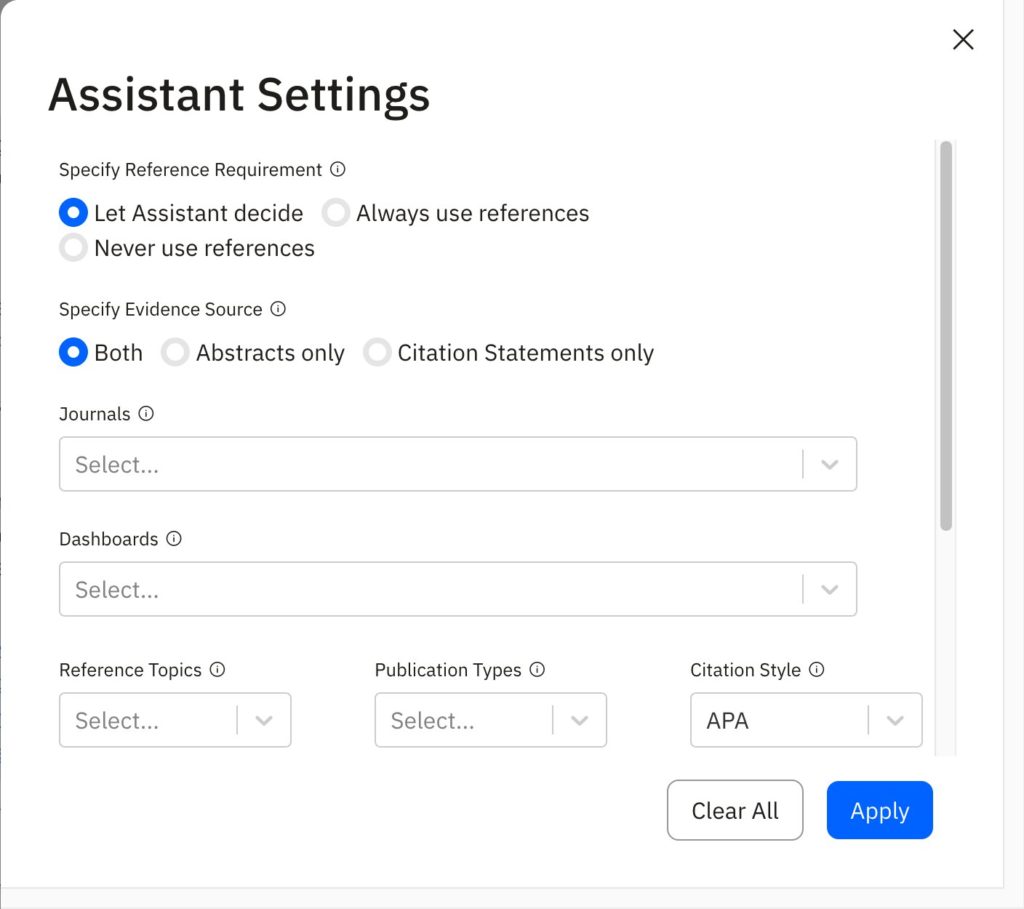
We will want to have some insight into the searches that are being run, so that we can verify that they are asking the right questions. From the demos I’ve seen of CoCounsel and Lexis+ AI, this is not currently a feature. But it could be. For example, the AI assistant from scite (an academic research tool) sends searches to academic research databases and (seemingly using RAG and other techniques to analyze the search results) produces an answer. They also give a mini-research trail, showing the searches that are being run against the database and then allowing you to adjust if that’s not what you wanted.
scite AI Assistant Sample ResultssCcite AI Assistant Settings
Are there uses for generative AI where the risks presented by hallucinations are lessened?
The other good news is that there are plenty of tasks we can give generative AI for which hallucinations are less of an issue. For example, CoCounsel has several other “skills” that do not depend upon accuracy of legal research, but are instead ways of working with and transforming documents that you provide to the tool.
Similarly, even working with a generally applicable tool such as ChatGPT, there are many applications that do not require precise legal accuracy. There are two rules of thumb I like to keep in mind when thinking about tasks to give to ChatGPT: (1) could this information be found via Google? and (2) is a somewhat average answer ok? (As one commentator memorably put it “Because [LLMs] work by predicting the most statistically likely word in a sentence, they churn out average content by design.”)
For most legal research questions, we could not find an answer using Google, which is why we turn to Westlaw or Lexis. But if we just need someone to explain the elements of breach of contract to us, or come up with hypotheticals to test our knowledge, it’s quite likely that content like that has appeared on the internet, and ChatGPT can generate something helpful.
Similarly, for many legal research questions, an average answer would not work, and we may need to be more in-depth in our answers. But for other tasks, an average answer is just fine. For example, if you need help coming up with an outline or an initial draft for a paper, there are likely hundreds of samples in the data set, and there is no need to reinvent the wheel, so ChatGPT or a similar product would work well.
What’s next?
In the coming months, as legal research generative AI products become increasingly available, librarians will need to adapt to develop methods for assessing accuracy. Currently, there appear to be no benchmarks to compare hallucinations across platforms. Knowing librarians, that won’t be the case for long, at least with respect to legal research.
Further reading
If you want to learn more about how retrieval augmented generation and vector embedding work within the context of generative AI, check out some of these sources:
Somewhat recently, during a webinar on generative AI, when the speaker Joe Regalia mentioned “flu snot” prompting, I was momentarily confused. What was that? Flu shot? Flu snot? I rewound a couple of times until I figured out he was saying “few shot” prompting. Looking for some examples of few-shot learning in the legal research/writing context, I Googled around and found his excellent article entitled ChatGPT and Legal Writing: The Perfect Union on the write.law website.
What Exactly is Few Shot Prompting?
It turns out that few-shot prompting is a technique for improving the performance of chatbots like ChatGPT by supplying a small set of examples (a few!) to guide its answers. This involves offering the AI several prompts with corresponding ideal responses, allowing it to generate more targeted and customized outputs. The purpose of this approach is to provide ChatGPT (or other generative AI) with explicit examples that reflect your desired tone, style, or level of detail.
Legal Research/Writing Prompting Advice from write.law
To learn more, I turned to Regalia’s detailed article which provides his comprehensive insights into legal research/writing prompts and illuminates various prompting strategies, including:
Zero Shot Learning/Prompting
This pertains to a language model’s ability to tackle a novel task, relying on its linguistic comprehension and pre-training insights. GPT excels in zero-shot tasks, attributed to its robust capabilities. (Perhaps unsurprisingly, one-shot learning involves providing the system with just one example.)
Few-Shot Learning/Prompting
Few-shot learning involves feeding GPT several illustrative prompts and responses that echo your desired output. These guiding examples wield more influence than mere parameters because they offer GPT a clear directive of your expectations. Even a singular example can be transformative in guiding its responses.
As an example of few-shot learning, he explains that if you want ChatGPT to improve verbs in your sentence, you can supply a few examples in a prompt like the following:
My sentence: The court issued a ruling on the motion.Better sentence: The court ruled on the motion. My sentence: The deadline was not met by the lawyers. Better sentence: The lawyers missed the deadline. My sentence: The court’s ruling is not released. [now enter the sentence you actually want to improve, hit enter, and GPT will take over] [GPT’s response] Better sentence: The court has not ruled yet [usually a much-improved version, but you may need to follow up with GPT a few times to get great results like this]
And Much More Prompting Advice!
Regalia’s website offers an abundance of insights as you can see from the extensive list of topics covered in his article. Get background information on how geneative AI system operate, and dive into subjects like chain of thought prompting, assigning roles to ChatGPT, using parameters, and much more.
What Legal Writers Need to Know About GPT
Chat GPT’s Strengths Out of the Box
Chat GPTs Current Weaknesses and Limitations
Getting Started with Chat GPT
Prompt Engineering for Legal Writers
Legal Writing Prompts You Can Use with GPT
Using GPT to Improve Your Writing
More GPT Legal Writing Examples for Inspiration
Key GPT Terms to Know
Final Thoughts for GPT and Legal Writers
Experimenting With Few-Shot Prompting Before I Knew the Name
Back in June 2023, I first started dabbling in few-shot prompting without even knowing it had a name, after I came across a Forbes article titled Train ChatGPT To Write Like You In 5 Easy Steps. Intrigued, I wondered if I could use this technique to easily generate a profusion of blog posts in my own personal writing style!!
I followed the article’s instructions, copying and pasting a few of my favorite blog posts into ChatGPT to show it the tone and patterns in my writing that I wanted it to emulate. The result was interesting, but in my humble opinion, the chatty chatbot failed to pick up on my convoluted conversational (and to me, rather humorous) approach. They say that getting good results from generative AI is an iterative process, so I repeatedly tried to convey that I am funny using a paragraph from a blog post:
Prompt: Further information. I try to be funny. Here is an example:During a text exchange with my sister complaining about our family traits, I unthinkingly quipped, “You can’t take the I out of inertia.” Lurching sideways in my chair, I excitedly wondered if this was only an appropriate new motto for the imaginary Gotschall family crest, or whether I had finally spontaneously coined a new pithy saying!? Many times have I Googled, hoping in vain, and vainly hoping, to have hit upon a word combo unheard of in Internet history and clever/pithy enough to be considered a saying, only to find that there’s nothing new under the virtual sun.
Fail! Sadly, my efforts were to no avail, it just didn’t sound much like me… (However, that didn’t stop me from asking ChatGPT to write a conclusion for this blog post!)
Conclusion
For those keen to delve deeper into the intricacies of legal research, writing, and the intersection with AI, checking out the resources on write.law is a must. The platform offers a wealth of information, expert insights, and practical advice that can be immensely valuable for both novices and seasoned professionals.