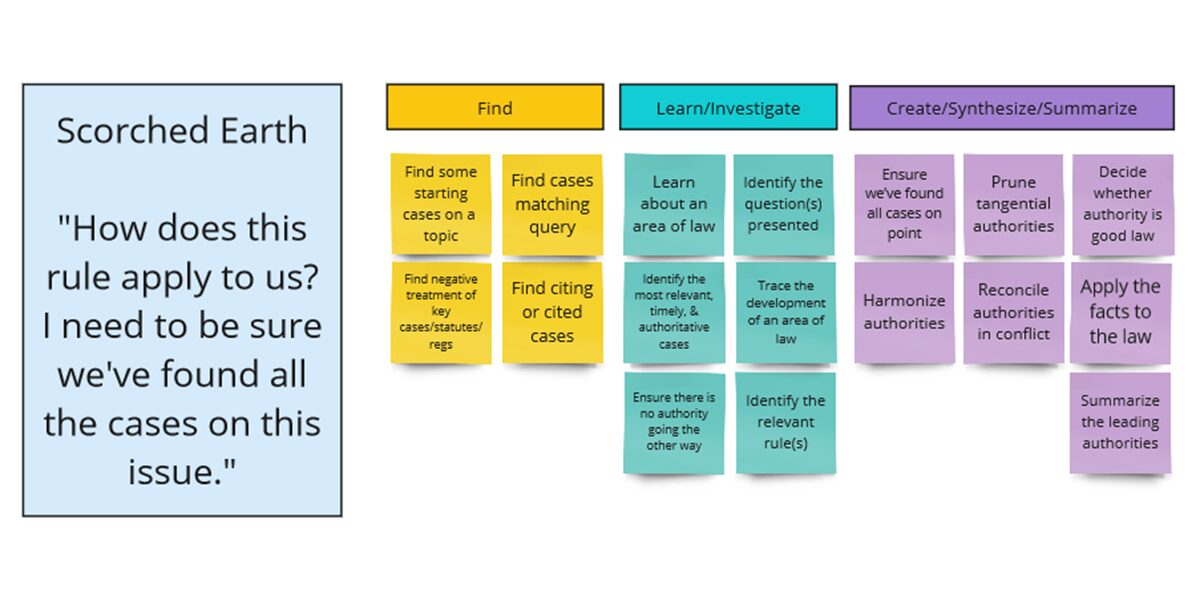
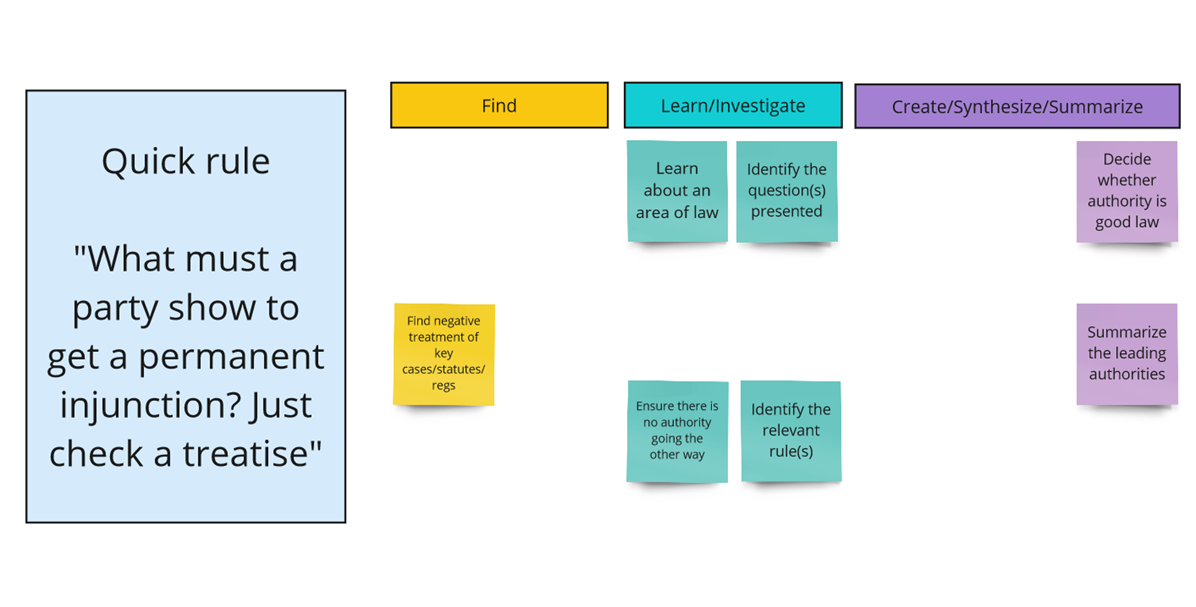
I had the pleasure of co-teaching AI and the Practice of Law with Kenton Brice last semester at OU Law. It was an incredible experience. When we met to think through how we would teach this course, we agreed on one crucial component:
We wanted the students to get a lot of reps using AI throughout the entire course.
That is fairly easy to accomplish for things like research, drafting, and general studying for the course but we hit a roadblock with the assessment component. I thought about it for a week and said, “Kenton, what if we created an AI that would Socratically quiz the students on the readings each week?” His response was, “Do you think you can do that?” I said, “I don’t know but I’ll give it a try.” 🤷♂️
Thus Socratic Quizbot was born. If you follow me on social media, you’ve probably seen me soliciting feedback on the paper:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4975804
December 2024 Update
Purpose
A lot of the motivation for Quizbot was a new paradigm in the law school ecosystem: the take-home essay is effectively dead. In fact, lots of the typical homework that you would assign as a law school professor simply breaks when you introduce something like ChatGPT or Claude into our world. We needed to come up with new methods of assessment.
I knew that these tools were really good at ingesting documents like PDFs and then summarizing them (manipulating the text, generating based on the text, etc.). What I needed was an AI that could read our course readings and then have a back-and-forth Socratic conversation with the students about those readings, and then some method to assess those conversations so that I could give students a grade. This felt like a big task with many potential pitfalls for one guy who is only mediocre (at best) at coding and app development.
As it turned out, I was able to fumble my way through the process and create a method of assessment that students seemed to enjoy. Alright, “enjoy” is probably too strong of a word, but they tolerated it and said they liked it quite a bit more than something like a multiple-choice test or a take-home essay. The Socratic Quizbot enables you to scale cold-calling to every student in the class while eliminating much of the stress and embarrassment that law students have dreaded since time immemorial.
Since many of the people who are interested in this blog post may have already read or skimmed my article, I decided to add my update as Appendix A so that you could simply fast-forward to the portion that is relevant to you. There is also a link to the open-source code in Github.
A Brief Overview of What is in Appendix A
Appendix A was born out of one question I kept getting after sharing the pre-print of my article: “How?” So, let me show you exactly how you can implement the Socratic Quizbot in your classroom, along with some insights from my students who graciously let me experiment with them.
Student Feedback, Challenges, and Improvements
Students overwhelmingly preferred this method to essays or multiple-choice quizzes, citing the flexibility to ask for clarification and control the pace of their learning. It also reduced the fear of being judged by their peers. That said, a few students tried to game the system by flipping the questions back on the bot. My grading rubric handled that, but I’d like to make Quizbot more persistent in pressing them for answers next time. I’m also excited to explore gamification—adding themes, Easter eggs, or playful interactions to make the experience even more enjoyable.
Two Ways to Get Started
If you want to try this yourself, you’ve got two paths. The no-code approach uses ChatGPT Teams and involves setting up a CustomGPT that ingests your course readings and quizzes your students. This is great if you’re looking for quick implementation. For the more tech-savvy or budget-conscious, the code-based option lets you host Quizbot locally using the instructions I’ve shared on GitHub. It takes a bit more effort but gives you total control over security and functionality. Hopefully you will see a version of Socratic Quizbot available in CALI.org in the future because I have been talking with John and Elmer and they both seem interested with integrating it into the platform (although, do not hold them to that because it’s still very-early talks).

Ultimately, my goal is to make this tool accessible for anyone in legal education. Whether you’re a tech whiz or new to AI, there’s a way to incorporate this into your classroom. And if you’re as curious about alternative assessments as I am, I’d love to hear your thoughts and ideas! The benefit of making it open in Github is that you can fork and improve my prototype. I would be deeply honored to see improvements on my little project and love to see what our community can do to improve it.