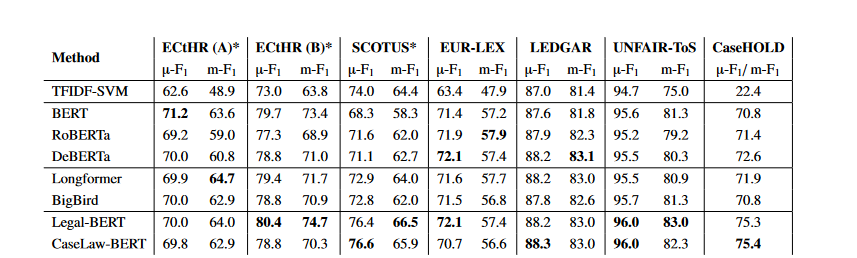
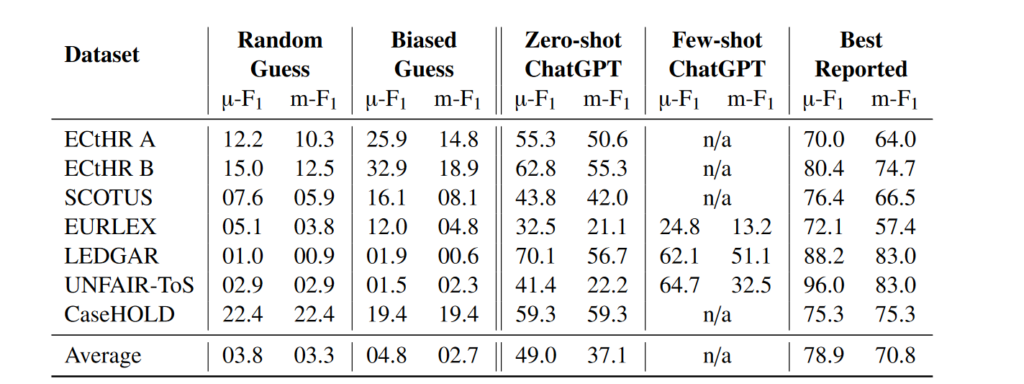
I haven’t quite gotten this whole ChatGPT thing. I’ve attended the webinars and the AALL sessions. I generally understand what it’s doing beneath the hood. But I haven’t been able to find a need in my life for ChatGPT to fill. The most relevant sessions for me were the AALS Technology Law Summer Webinar Series with Tracy Norton of Louisiana State University. She has real-world day-to-day examples of when she has been able to utilize ChatGPT, including creating a writing schedule and getting suggestions on professional development throughout a career. Those still just didn’t tip the balance for me.
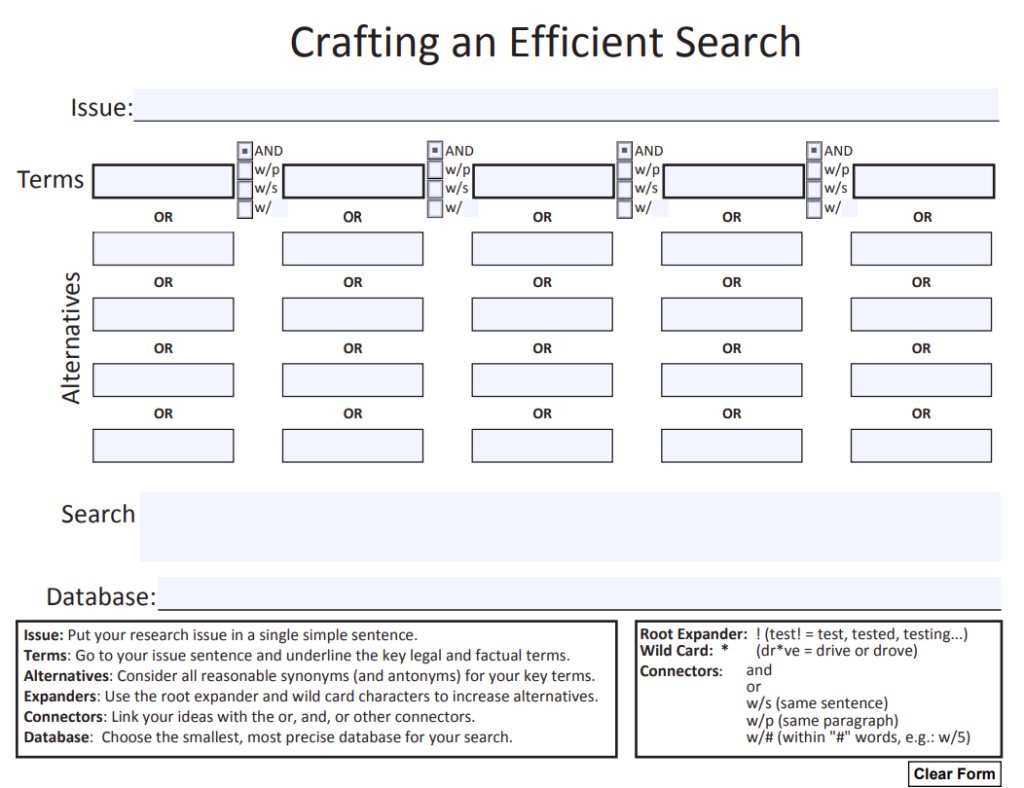
A few weeks ago, I presented to one of our legal clinics and demonstrated a form that our Associate Director, Tara Mospan, created for crafting an efficient search query. At its heart, the form is a visual representation of how terms and connectors work with each other. Five columns of five boxes, each column represents variations of a term, and connectors between the columns. For a drunk driving case, the term in the first box could be car, and below that we would put synonyms like vehicle or automobile. The second column could include drunk, inebriated, and intoxicated. And we would choose the connector between the columns, whether it be AND, w/p, w/s, or w/#. Then, we write out the whole search query at the bottom: (car OR vehicle OR automobile) w/s (drunk OR inebriated OR intoxicated).
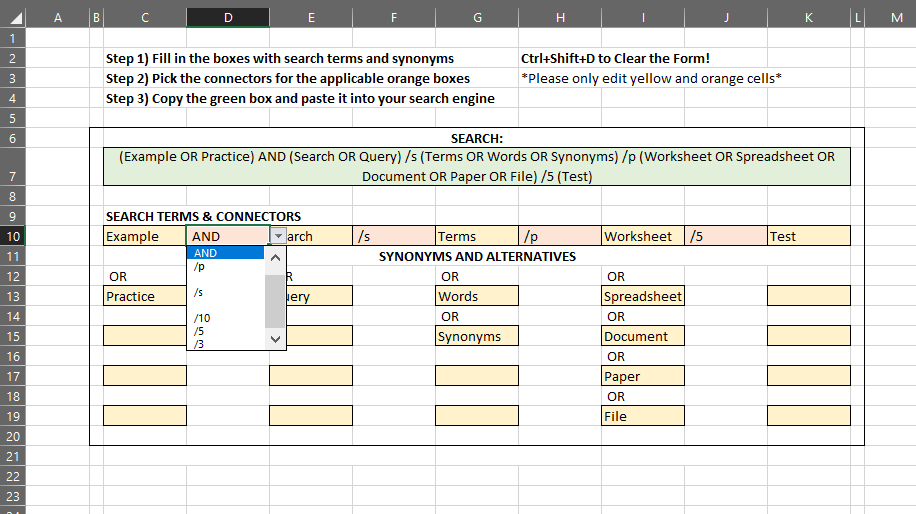
After the presentation, I offered a student some extra copies of the form. She said no, that I presented to her legal writing class last year and she was so taken with the form that she had recreated it in Excel. Not only that, she used macros to transform the entered terms into a final query. I was impressed and asked her to send me a copy. It was exactly as she had described, using basic commands to put the terms together, with OR between terms within a column, and drop downs of connectors. She had taken our static form and transformed it into a dynamic utility.
Now I was inspired: What if I could combine the features of her Excel document with the clean layout of our PDF form? Finally, I saw a use for ChatGPT in my own life. I had read about how well ChatGPT does with programming and it seemed like the perfect application. It could help me create a fillable PDF, with nuanced JavaScript code to make it easy to use and visually appealing.
I went into ChatGPT and wrote out my initial command:
I am trying to create a fillable PDF. It will consist of five columns of text boxes, and each column will have five boxes. Search terms will be placed in the boxes, although not necessarily in every box. There will be a text box at the bottom where the terms from the boxes above will be combined into a string. When there are entries in multiple boxes in a column, I want the output to put a set of parentheses around the terms and the word OR between each term.
ChatGPT immediately gave me a list of steps, including the JavaScript code for the results box. I excitedly followed the directions to the letter, saved my document, and tested it out. I typed car into the first box and…nothing. It didn’t show up in the results box. I told ChatGPT the problem:
The code does not seem to be working. When I enter terms in the boxes, the text box at the bottom doesn’t display anything.
And this began our back and forth. The whole process took around four hours. I would explain what I wanted, it would provide code, and I would test it. When there were errors, I would note the errors and it would try again. A couple times, the fix to a minor error would start snowballing into a major error, and I would need to go back to the last working version and start over from there. It was a lot like having a programming expert working with you, if they had infinite patience but sometimes lacked basic understanding of what you were asking.
For many things, I had to go step-by-step to work through a problem. Take the connectors, for example. I initially just had AND between them as a placeholder. I asked it to replace the AND with a drop-down menu to choose the connector. The first implementation of this ended up replacing OR between the synonyms instead of the second needed search term. We went back and forth until the connector option worked between the first two columns of terms. Then we worked through the connector between columns two and three, and so on.
At times, it was slow going, but it was still much faster than learning enough JavaScript to program it myself. ChatGPT was also able to easily program minor changes that made the form much more attractive, like not having parentheses appear unless there are two terms in a column, and not displaying the connector unless there are terms entered on both sides of it. And I was able to add a “clear form” button at the end that cleared all of the boxes and reverted the connectors back to the AND option, with only one exchange with ChatGPT.
Overall, it was an excellent introduction to at least one function of AI. I started with a specific idea and ended up with a tangible product that functioned as I initially desired. It was a bit more labor intensive than the articles I’ve read led me to believe, but the end result works better than I ever would have imagined. And more than anything, it has gotten me to start thinking about other projects and possibilities to try with ChatGPT.