

Guest post from Andrew Dang, ASU Law Student and LLM Developer.
The language of law has many layers. Legal facts are more than objective truths; they tell the story and ultimately decide who wins or loses. A statute can have multiple interpretations, and those interpretations depend on factors like the judge, context, purpose, and history of the statute. Legal language has distinct features, including rare legal terms of art like “restrictive covenant,” “promissory estoppel,” “tort,” and “novation.” This complex legal terminology poses challenges for normal semantic search queries.
Vector databases represent an exciting new trend, and for good reason. Rather than relying on traditional Boolean logic, semantic search leverages word associations by creating embeddings and storing them in a vector database. In machine learning and natural language processing, embeddings depict words or sentences as dense vectors of real numbers in a continuous vector space. This numerical representation of text is typically generated by a model that tokenizes the text and learns embeddings from the data. Vectors capture the contextual and semantic meaning of each word. When a user makes a semantic query, the search system works to interpret their intent and context. The system then breaks the query into individual words or tokens, converts them into vector representations using embedding models, and returns ranked results based on their relevance. Unlike Boolean search which requires specific syntax, (“AND”, “OR”, etc.) semantic search allows for queries in natural language and opens up a whole new world of potential when searches are not constrained by the rules of exact matching of text.
However, legal language differs from everyday language. The large number of technical terms, the careful precision, and the fluid interpretations inherent in law mean that semantic search systems may fail to grasp the context and nuances of legal queries. The interconnected and evolving nature of legal concepts poses challenges in neatly mapping them into an embedding space representation. One potential way to improve semantic search in the legal domain is by enhancing the underlying embedding models. Embedding models are often trained on generalized corpora like Wikipedia, giving them a broad but shallow understanding of law. This surface-level comprehension proves insufficient for legal queries, which may seem simple but have layers of nuance. For example, when asked to retrieve the key facts of a case, an embedding model might struggle to discern what facts are relevant versus extraneous details.
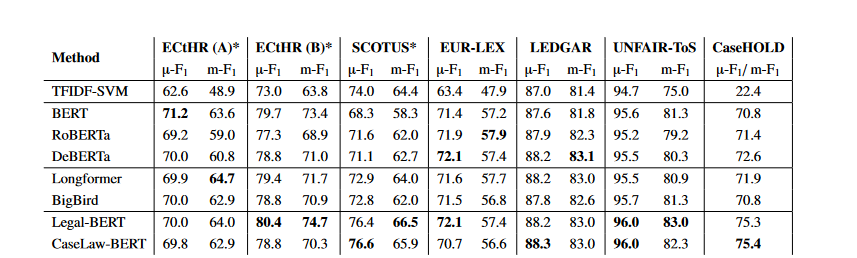
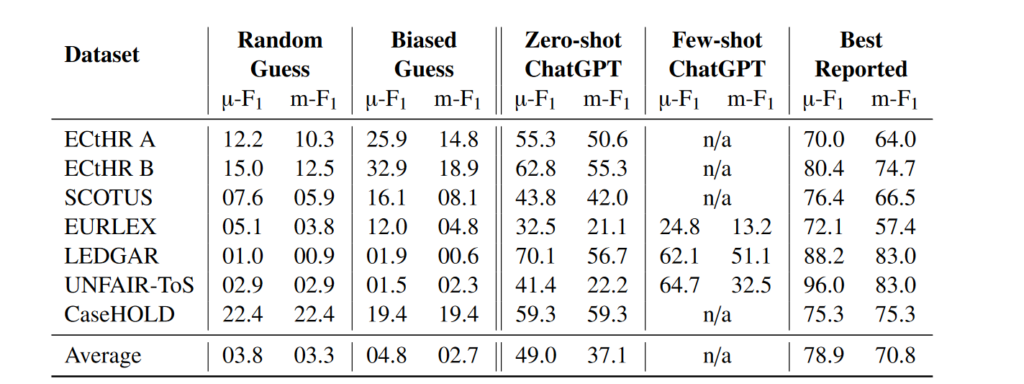
The model may also fail to distinguish between majority and dissenting opinions due to a lack of legal background needed to make such differentiations. Training models on domain-specific legal data represents one promising approach to overcoming these difficulties. By training on in-depth legal corpora, embeddings could better capture the subtleties of legal language, ideas, and reasoning. For example, Legal Bert, which stands for Bidirectional Encoder Representations was pre-trained on the CaseHold dataset. The size of this corpus (37GB) is large, representing 3,446,187 legal decisions across all federal and state courts. The CaseHold data set is larger than the size of the Book Corpus/Wikipedia corpus originally used to train the BERT model. When tested on the LexGlue benchmark- a benchmark dataset to evaluate the performance of NLP methods in legal tasks, Legal Bert performed better than ChatGPT.
Semantic search shows promise for transforming legal research, but realizing its full potential in the legal domain poses challenges. Legal language is complex and can make it difficult for generalized embedding models to grasp the nuances of legal queries. However, recent optimized legal embedding models indicate these hurdles can be overcome by training on ample in-domain data. Still, comprehensively encoding the interconnected, evolving nature of legal doctrines into a unified embedding space remains an open research problem. Hybrid approaches combining Boolean and vector models are a promising new frontier that many researchers are exploring.
Realizing the full potential of semantic search for law remains an ambitious goal requiring innovative techniques. But the payoff could be immense – responsive, accurate AI assistance for case law research and analysis. While still in its promising infancy, the continued maturation of semantic legal search could profoundly augment the capabilities of legal professionals. A shift from generic to domain-specific models holds promise.
Andrew, Thanks for this excellent post.
Given the CaseHold dataset and existing technologies, such as sentiment and citation analysis, is automating the creation of an open-source citator imminent?
To the extent that you can use RAG to minimize hallucinations and use Legal Bert, are there hurdles beyond ingesting cases that have subsequently become ‘bad’ law (which could be largely addressed with a citator tool)?
Thanks, Jonathan
Hi Jonathan,
Thanks for reaching out. I can’t provide a definitive answer about the immediacy of automating an open-source citator. I haven’t fully explored citation research yet.(added to the list)
However, in relation to ‘bad law’, Casetext has constructed a dataset to identify overruling sentences in legal decisions. Using RAG to minimize hallucinations combined with Legal Bert could be promising. Yet, beyond ingesting cases labeled as ‘bad law’, there could be additional challenges that might not be fully addressed with a citator tool alone.
Heres the link to the Overuling datset
https://paperswithcode.com/dataset/overruling